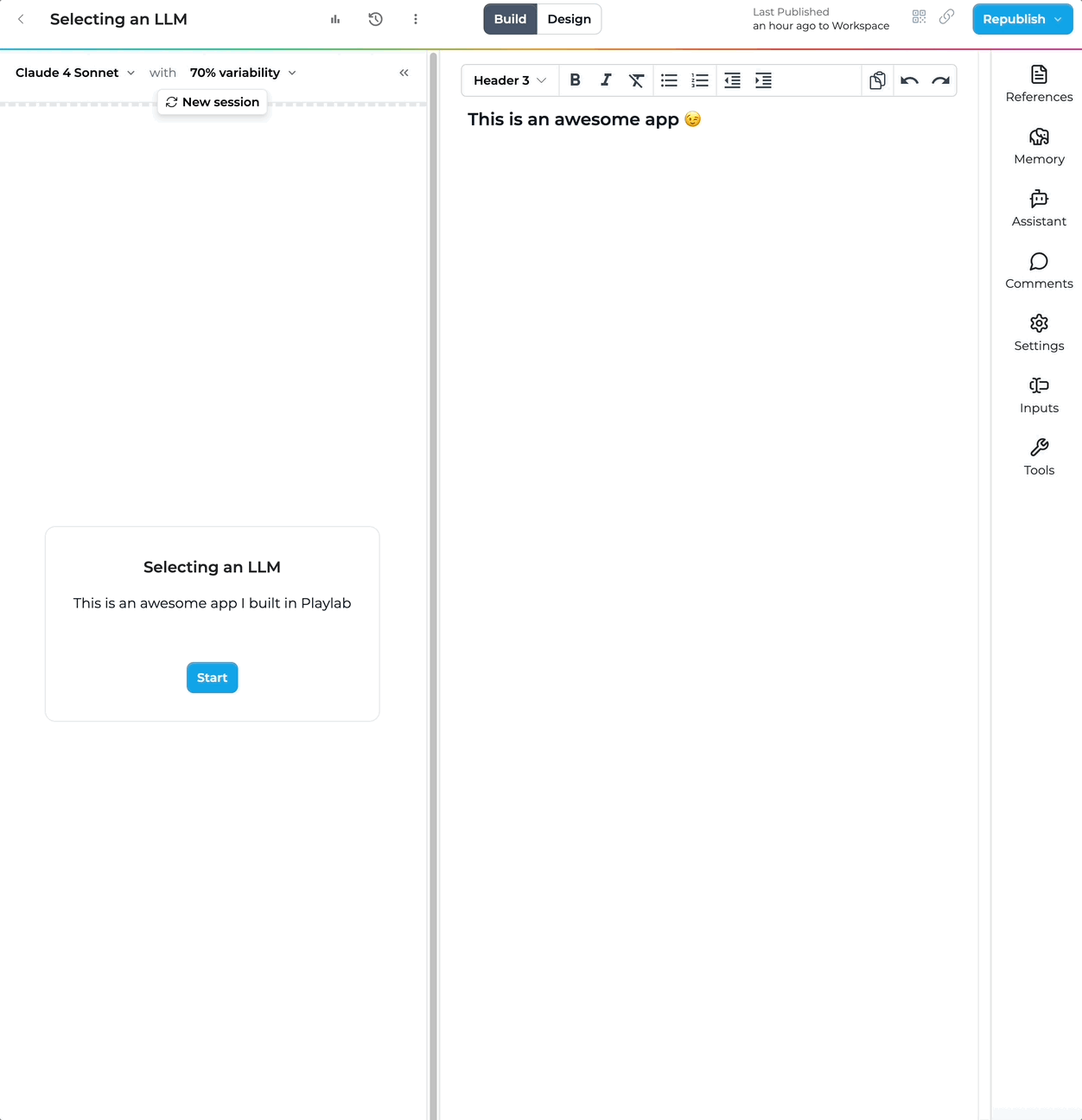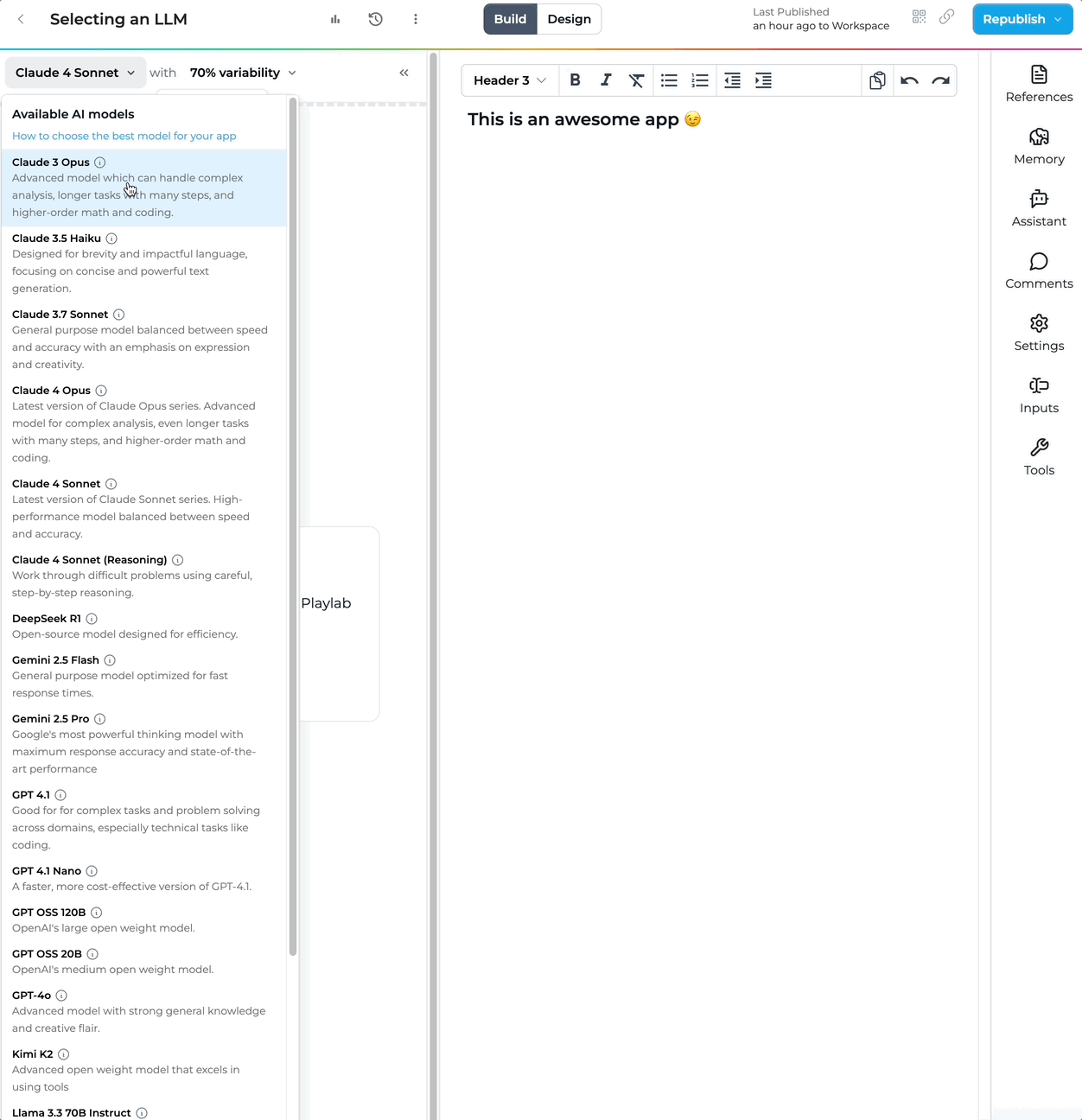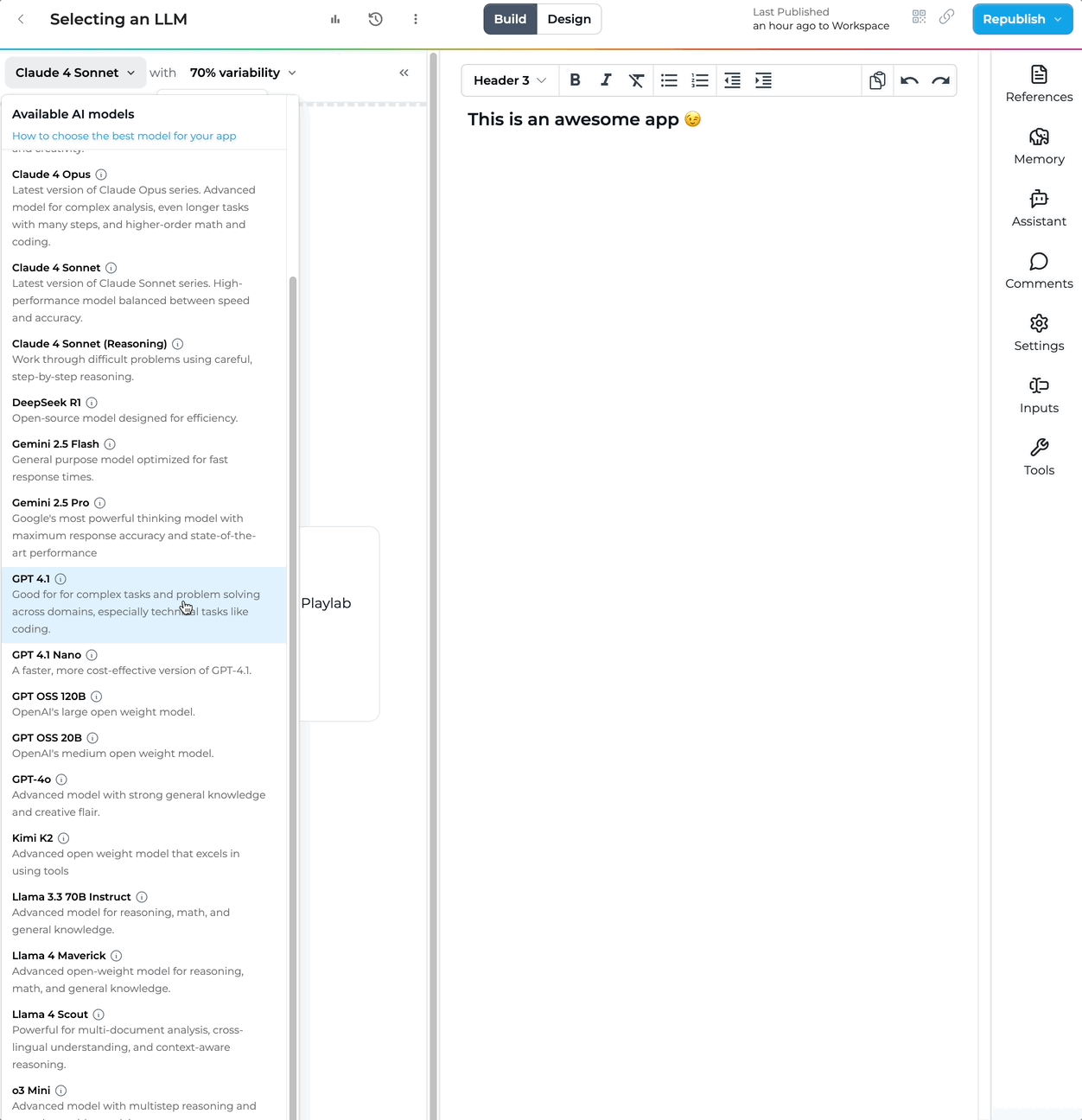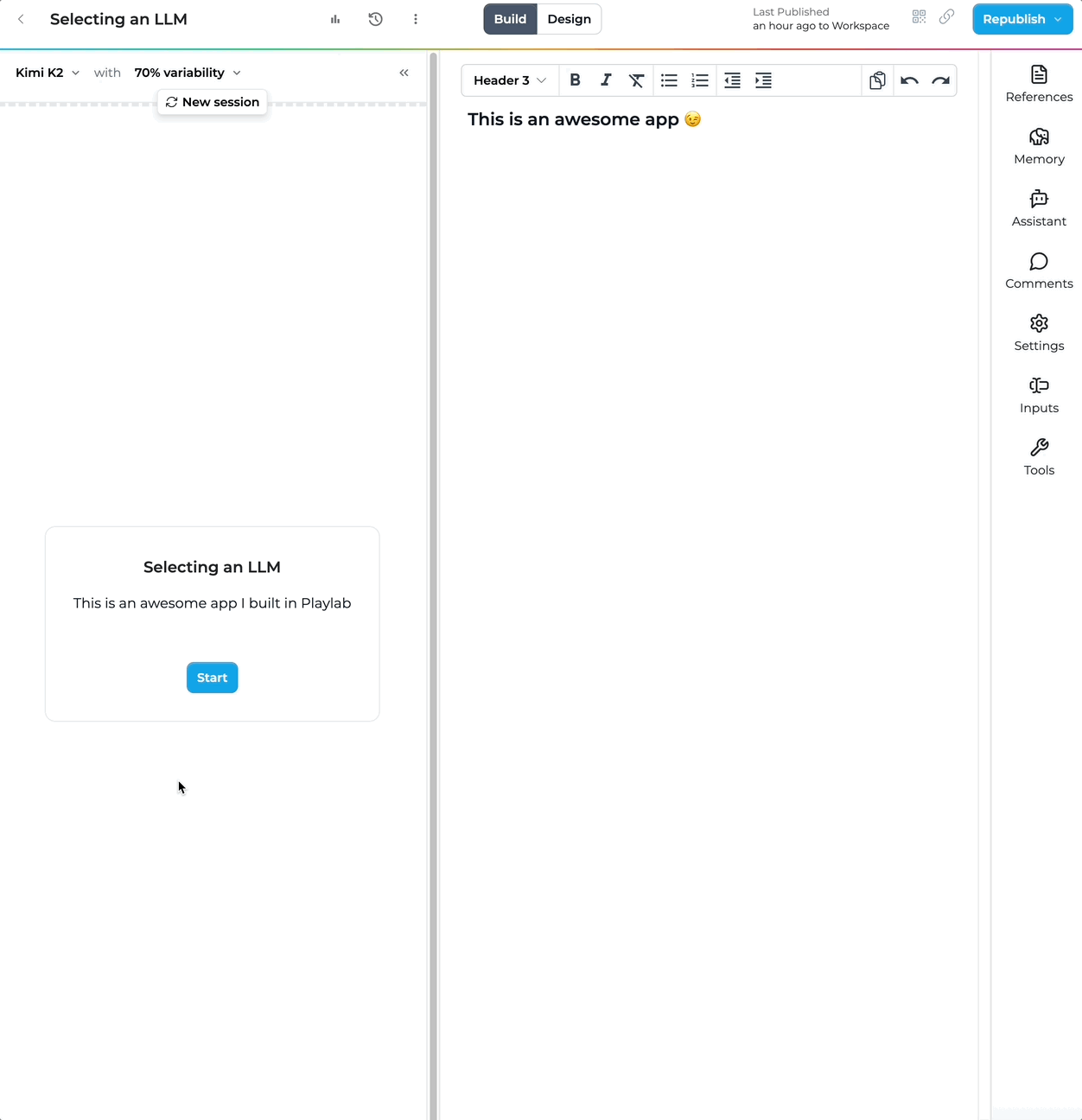
Description: Advanced model for complex analysis, even longer tasks with many steps, and higher-order math and coding.
Knowledge Cutoff: Aug 2025
Strengths: Unmatched intelligence and reasoning depth. Superior performance on complex multi-step problems. Exceptional analytical and coding capabilities. Best-in-class for higher-order math and extended tasks.
Trade Offs: Slower response times and higher cost. Best reserved for tasks that truly require maximum capability.
Description: Latest version of Claude Sonnet series - with the highest intelligence across most tasks.
Knowledge Cutoff: Aug 2025
Strengths: Highest intelligence across most tasks. Superior instruction following and nuance understanding. Exceptional balance of speed and capability. Best-in-class for most applications requiring high quality output.
Trade Offs: More expensive than smaller models. May be more than needed for very simple tasks.
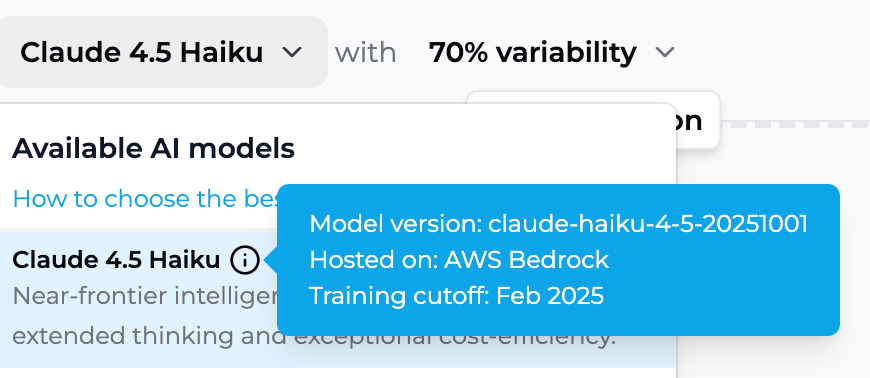
Description: Near-frontier intelligence at blazing speeds with extended thinking and exceptional cost-efficiency.
Knowledge Cutoff: July 2025
Strengths: Blazing fast response times with extended thinking capabilities. Near-frontier intelligence at exceptional cost-efficiency. Excellent for quick questions and lightweight tasks.
Trade Offs: Less capable than Sonnet or Opus models. May struggle with complex multi-step reasoning and advanced analysis.
Description: Work through difficult problems using careful, step-by-step reasoning.
Knowledge Cutoff: Aug 2025
Strengths: Exceptional step by step reasoning capabilities. Stronger at math and coding. Very good at explaining thought process.
Trade Offs: Slower response times. Not as optimized for creative tasks. Consider Claude Sonnet 4.6 or Claude Opus 4.6 for better overall performance.
Description: OpenAI's latest coding and reasoning model.
Knowledge Cutoff: Aug 2025
Strengths: State-of-the-art coding and reasoning performance. Exceptional problem-solving capabilities. Superior instruction following and nuance understanding.
Trade Offs: Slower response times and higher cost. May be unnecessary for simple tasks. Premium pricing for cutting-edge capabilities.
Description: Faster model for well-defined tasks.
Knowledge Cutoff: Aug 2025
Strengths: Fast response times for well-defined tasks. Cost-effective for regular applications. Strong performance across most tasks without premium overhead.
Trade Offs: Slightly reduced capabilities compared to GPT 5.4. May not excel at the most complex reasoning challenges requiring maximum model capacity.
Description: Google's most powerful thinking model with maximum response accuracy and state-of-the-art performance.
Knowledge Cutoff: Jan 2025
Strengths: Maximum response accuracy and state-of-the-art performance. Exceptional reasoning and problem-solving. Superior performance on complex analytical tasks. Enhanced creative and coding capabilities. Best-in-class for applications requiring advanced Google AI.
Trade Offs: Slower response times compared to Flash models. Higher cost for premium capabilities. May be unnecessary for simple tasks.
Description: Google's frontier-tier Flash model for agentic and coding workflows. Outperforms Gemini 3.1 Pro on coding and agentic benchmarks while running roughly four times faster.
Knowledge Cutoff: Jan 2026
Strengths: Frontier-level performance on coding and agentic tasks at Flash-tier speed. Strong multimodal understanding across text, image, audio, and video. 1M-token input context for long-horizon, multi-step workflows.
Trade Offs: Roughly 3x the per-token cost of Gemini 3 Flash. Dynamic thinking on by default may add latency for very simple prompts.
Description: General purpose model optimized for fast response times.
Knowledge Cutoff: Jan 2025
Strengths: Extremely fast response times. Strong general-purpose performance. Good for simple instruction following and high volume tasks.
Trade Offs: Not ideal for multi-step problem solving or complex instruction following. May miss nuance in instructions.
Description: Mistral's 675B parameter flagship model with strong multilingual capabilities.
Knowledge Cutoff: Oct 2024
Strengths: Strong reasoning and analytical capabilities. Excellent multilingual support. Open weight flexibility for customization and deployment.
Trade Offs: May not match top frontier models on the most demanding tasks. Performance varies by domain.
Description: Advanced open weight model that excels in using tools.
Knowledge Cutoff: \~Apr 2024
Strengths: Excellent tool usage capabilities. Good for applications requiring API integrations. Strong technical reasoning.
Trade Offs: May be specialized for tool use rather than general conversation. Performance varies on creative tasks.
Description: Open-source model designed for efficiency.
Knowledge Cutoff: July 2024
Strengths: Cost-effective and efficient. Good for applications where budget is a primary concern. Open-source flexibility.
Trade Offs: May not match performance of frontier models on complex tasks. Limited compared to more advanced models.
Description: Advanced open-weight model for reasoning, math, and general knowledge.
Knowledge Cutoff: Aug 2024
Strengths: Strong reasoning capabilities for math and general knowledge. Open weight benefits. Good performance across diverse tasks.
Trade Offs: Not as fast as smaller models. May require more specific prompting for best results.
Description: Powerful for multi-document analysis, cross-lingual understanding, and context-aware reasoning.
Knowledge Cutoff: Aug 2024
Strengths: Excellent at analyzing multiple documents simultaneously. Strong cross-lingual capabilities. Advanced contextual understanding.
Trade Offs: May be slower for simple tasks. Specialized for document analysis rather than general usage.
Description: Advanced model for reasoning, math, and general knowledge.
Knowledge Cutoff: Dec 2023
Strengths: Strong general well balanced use cases. Performs well in math. Effective at following clear instructions. Open weight flexibility.
Trade Offs: Slower than smaller models. Does not follow instructions as well as Claude/GPT models.
Description: Large-scale Qwen3 model with 235B parameters, optimized for instruction following and reasoning tasks.
Knowledge Cutoff: Oct 2023
Strengths: Excellent multilingual support. Strong performance on reasoning and instruction following tasks. Good balance of performance and efficiency. Open weight flexibility.
Trade Offs: May not match frontier model performance on highly specialized tasks. Performance varies depending on language and domain.